Hackathon - Document Search Solution¶
Overview¶
This repo contains source code from the backend component that we implemented in our Document Search Solution on mobile in the One Mount Hackathon contest that was organized in Ha Noi, 2021. Our solution matches with feasibility to implement and be a workable prototype.
Our application contains a search engine to search all legal documents in our company, and solved problems that we faced in our workplace:
-
It supports full-text search instead of searching from metadata only (title, abstracts, short description,...), which reduces the time to deep-dive into the body of the document when the users see matches with the keyword.
-
It centralizes knowledge, follows the
single source of truthprinciple, and is served through a friendly UI in mobile. -
It contains interactive modules that connect with user data, such as search behaviors, related documents to build a persona box with useful information.
Logic Implemented¶
By researching a lot of paper walkthroughs, we adopt the following components that we try to deploy to our systems.
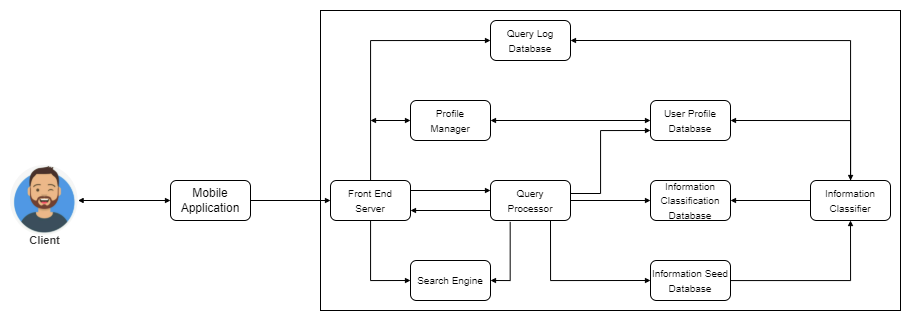
Architecture¶
By leveraging our cloud infrastructure, we used a lot of products offered by Google to deliver our backend components:
-
Schedule, Functions: Cloud Schedule, Cloud Functions, Data Proc
-
Text Extract, Transformation: Translation API, Vision API, Natural Language API
-
Storage: BigQuery, Cloud Storage
Then, we use low-code Outsystems to build Front End component that will pack our information and served it through the mobile application. We put Front End/Back End in different virtual machine instances (for securities purposes)
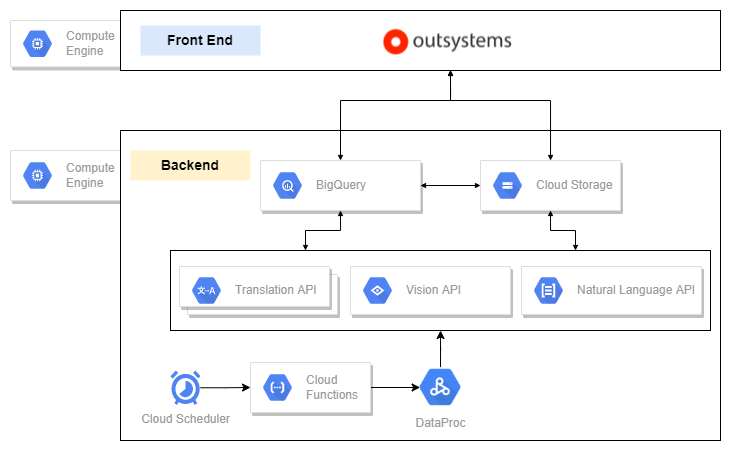
Based on that, behind the scenes, we have designed a data pipeline to extract information and information from our document.
Data Pipeline¶
There is a consistent process that the Back End component will cover for the document journeys. The diagram below will show that:
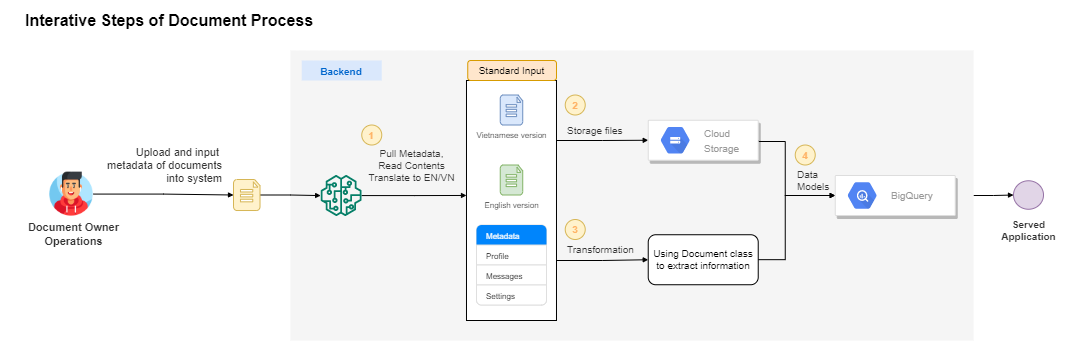
When document owners or operators publish a document into the system, the Backend then triggers the following four steps:
Step 1: Metadata, Document Read.
This step pulls metadata of the document based on the fill-in of the user through operation UI with the below sample:
metadata:
entity: Company Sample A
language: VIE
number: "No. 120"
issued_date: 2021-11-04
effective_date: 2022-01-01
source: Business Development
subject: Strategic Opportunities Template
title: Strategic Opportunities Template
type: Internal Regulation
is_internal: true
The number of annotating metadata from a document will be increased time-to-time because it can be input by the document owner or operators, some can be extracted automatically based on text mapping then still need to be verified later.
Then, we read the document and convert it into a text file *.txt and translate English/Vietnamese depending on the language of the document.
The endpoint of this step has three files: metadata in .yml, two text files in desired languages
Step 2: At our core, we designed a Document class that has some methods listed below:
Method of Document class table
| Method | Feature | Description | Is Public |
|---|---|---|---|
| _read_document | Process document | Process to parse document information from files, supported file type are text *.txt, word (*.doc, *.docx), and with Vision API, we can support PDF files (*.pdf) and images (*.png) | False |
| _extract_document | Extract Content | Based on the processed text, we parse the document into one dictionary paragraphs, sentences, words for both English and Vietnamese, return a dictionary of position and types relative | False |
| _parse_dictionary | Separated Content Components | Separated dictionary into single dictionary with following synopsis {'position': number, 'components': string} | False |
| _get_unique_words | Tokens create | Created set of words using in document | False |
| _content_to_df | Document tabular form | Parse content of document into data frame | False |
| check_valid_ext | Util - Validation extension of file | Check for the extension of the file with target extension | True |
| _check_file | Util - Validation file exists | If the file exists, return True, else False, instead of error | False |
| get_id | Get the ID of Document | Hashed generate based on the file name. Example: Db9c73ec7aee3cbc103a29d07938b5c39 | True |
| get_document | Get document | Document text that read from source | True |
| get_content | Get contents | Dictionary of all components of the document, including paragraphs, sentences, words | True |
| get_paragraphs | Get paragraphs | Dictionary of paragraphs only. Example: {'position': 1, 'paragraph': "This is first paragraph, included multiple rows"} | True |
| get_sentences | Get sentences | Dictionary of sentences only. Example: {'position': 1, 'sentence': "This is first sentence"} | True |
| get_words | Get words | Dictionary of words only. Example: {'position': 1, 'word': "This"} | True |
| get_tokens | Get lists | Array that contains set of words | True |
| get_metadata | Get Metadata | Dictionary of metadata that get from document owner | True |
| to_dataframe | Get Dataframe | Dataframe of document | True |
| statistics | Document basic statistics | Dictionary of basic statistics, count number of contents (number of paragraphs, number of sentences, number of words) | True |
| write_excel | Write to Excel | Write data frame into excel file | True |
| write_parquet | Write to Parquet | Write dataframe into parquet file | True |
| update_metadata | Update Metadata | When there are updated metadata information, then we trigger information related to document | True |
| search | Simple search backbone by thefuzz library | Search keyword in a document then returned related components with limit and threshold | True |
Step 3: Storage Output
We then store the output we gather from steps 1 and 2 into a database:
-
Raw files [Uploaded file, Process Text, Translated Text, Metadata] will go to Cloud Storage.
-
The content of the document in the data frame will go to BigQuery to transform around more steps to become useful information.
Step 4: Data Model
Based on the data from step 3, we can generate various useful targeted outputs that support use-case in the UI functional. We then, combined from both user search processors, the related of the document to create new data models and backed by using dbt (data build tool) in BigQuery environment.
Let example:
- Synonym Keyword: all suggest related words based on keywords, separated by
|.
- Most Search: at least top-N search in a period.
We then can serve it through API for Front End can get from that with updated data, can be in real-time.
Quickstart¶
So at this repo, we mirror steps 1 and 2 which cover the baking journey from sources and focus on the usage of Document class. Below will represent the source code folders and files hierarchy.
.
data/ # Contain dataset
src/ # Contain `src` component
|____ document/
|____ file/
|____ util/
__init__.py
.gitignore
config.py # Configuration file
extract.py # Extract Document Information
metadata.py # Parse metadata
README.md # Project indtroduction
Makefile # Automation with target
requirements.txt # Dependencies
[1] Installment:
a) Python at version >= 3.9 [Minor at 3.9.1]
b) Install dependencies
seaborn==0.11.2
thefuzz==0.19.0
pandas>=1.1.0
nltk>=3.5
pyarrow>=7.0.0
matplotlib==3.5.2
[2] Configuration:
To intergrate with the pipeline, you can modify global component on the config file.
#!/bin/python3
# Global
import sys
import os
# Path Append
sys.path.append(os.path.abspath(os.curdir))
# Declare
# Temporary folder, which contains a log file
TEMP_DIR = os.path.join('temp')
# Source of files, which has been stored raw file from uploaded document.
SOURCE_DIR = os.path.join('data', 'source')
# Source of processed file and data extraction.
OUTPUT_DIR = os.path.join(TEMP_DIR, 'document')
# File support
SUPPORTED_FILE_TYPE: list[str] = ["*.doc", "*.docx", "*.doc", "*.txt"]
# Truncated legth threshold
TRUNCATED_LENGTH: int = 500
# Metadata selekon
METADATA_SKLETON: dict[str, dict] = {
'metadata': {
'language': None,
'title': None,
'subject': None,
'entity': None,
'source': None,
'number': None,
'type': None,
'issued_date': None,
'effective_date': None,
'is_internal': False
}
}
Remember this, this can be largely based on the file sizes, so remember to put the file into .gitignore to not affect the codebase.
Based on the number of handle read the document from file type, we can extend or reduced the glob file extension we can support. SUPPORTED_FILE_TYPE currently support [".doc", ".docx", ".doc", ".txt"].
[3] Using CLI to interactive with module:
Added metadata for the source folder, if not exists related *.yml file.
Extract information and send it to the destination folder.
or, with Makefile, we will have 2 targets that automatically process above. You can change the config variables declared with the document_* prefix.
#!/bin/bash
# Default Shell
SHELL := /usr/bin/bash
# Folder
SOURCE_DIR = data/source
DESTINATION_DIR = temp/document
metadata:
python metadata.py --source ${SOURCE_DIR}
extract:
python extract.py --source ${SOURCE_DIR} --destination ${DESTINATION_DIR}
Then, we can use it by below command:
After all, you can see all things in the destination folder. Example:
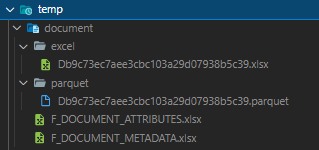
with:
F_DOCUMENT_METADATA.xlsx will likely like this

F_DOCUMENT_METADATA.xlsx will likely like this
Note¶
-
Replica Source Code: This is just fragmented code, represented around 50% proposition compared to what we implemented in the contest. Its has enhancement with code style and package it into a module. For the impelement of
Documentclass, reference to Appendix 1: Source Code part -
We welcome idea contributions and comments/feedback for our solution.
Reference¶
- Text Analysis Pipelines [Towards Ad-hoc Large-Scale Text Mining] of Henning Wachsmuth
Appendix¶
Appendix 1: Source Code¶
Source code design for document class
#!/bin/python3
# Global
import os
import string
import re
import hashlib
# External
import pandas as pd
import yaml
from thefuzz import process
class Document:
"""Document is a class represented for any files in various type (txt, path, png)
then bake it into a mechanic to enrich document metadatas.
Return:
[Document]: Document Class
Example:
samp = Document(path='data/source/sample.txt')
samp.write_parquet('temp/t.parquet')
samp.write_excel('temp/t.xlsx')
"""
def __init__(self, path: str = None):
# Mechanic
self.path = path
self.original_path, self.file = os.path.split(self.path)
self.file_name, self.file_ext = os.path.splitext(self.file)
self.file_metadata = os.path.join(self.original_path, self.file_name + ".yml")
metadata = {}
if os.path.isfile(self.file_metadata):
try:
with open(self.file_metadata) as f:
component: dict = yaml.load(f, Loader=yaml.FullLoader)
metadata = component.get('metadata')
except Exception:
self.file_metadata = None
raise Exception
else:
import subprocess
try:
subprocess.run(
args=['python', 'metadata.py', '--file', self.file_metadata],
capture_output=True,
text=True,
check = True,
timeout=60
)
except Exception:
self.file_metadata = None
raise Exception
# Attribute
self.language = safe_dict_extract(d = metadata, key = 'language')
self.title = safe_dict_extract(d = metadata, key = 'title')
self.subject = safe_dict_extract(d = metadata, key = 'subject')
self.entity = safe_dict_extract(d = metadata, key = 'entity')
self.source = safe_dict_extract(d = metadata, key = 'source')
self.number = safe_dict_extract(d = metadata, key = 'number')
self.type = safe_dict_extract(d = metadata, key = 'type')
self.issued_date = safe_dict_extract(d = metadata, key = 'issued-date')
self.effective_date = safe_dict_extract(d = metadata, key = 'effective-date')
self.is_internal = safe_dict_extract(d = metadata, key = 'is-internal')
# Component
self.id = f"D{hashlib.md5(self.file.encode()).hexdigest()}"
self.document = self._read_document()
self.content = self._extract_content()
self.paragraphs, self.sentences, self.words = self._parse_dictionary()
self.tokens = self._get_unique_words()
self.document_dataframe = self._content_to_df()
def _read_document(self):
# Validate File Exits
if not os.path.isfile(self.path):
raise FileNotFoundError('There are folder, not exists any file. Check your path')
# Processing
if self.file_ext == ".txt":
with open(self.path, encoding='UTF-8') as f:
cont = f.read()
elif self.file_ext in (".doc", ".docx"):
import textract
parse_content = textract.process(self.path, input_encoding='UTF-8', output_encoding='UTF-8', extension=self.file_ext).decode('UTF-8')
cont = ''.join(parse_content)
else:
raise Exception(f"Currently not supported this extentsion {self.file_ext}")
# Decoding
content = cont.encode('UTF-8', "ignore").decode('UTF-8')
# Replace Whitespace
# \u200b is a "zero-width-space" in Unicode.
# Ref: https://stackoverflow.com/questions/35657620/illegal-character-error-u200b
content = content.replace('\u200b', ' ').replace(' ', ' ')
# Special Chraracter
# Ref: https://stackoverflow.com/questions/5843518/remove-all-special-characters-punctuation-and-spaces-from-string
content = re.sub(r'\W+', ' ', content).strip()
return content
def _extract_content(self):
# Special Character
# b'\xe2\x80\x93' -> TODO: Need to revert to bytes then excluded Special characters
# Define
contents = {}
_paragraph = list(filter(lambda x: x not in ('', string.punctuation), self.document.split('\n\n')))
# Paragraphs
for ind_par, par in zip(range(1, len(_paragraph) + 1), _paragraph):
sentences = {}
_sentences = list(filter(lambda x: x not in ('', string.punctuation), par.split(r'\.')))
# Sentences
for ind_sen, sen in zip(range(1, len(_sentences) + 1), _sentences):
words = {}
_words = list(filter(lambda x: x not in ('', string.punctuation), sen.split()))
# Words
for ind_wor, wor in zip(range(1, len(_words) + 1), _words):
words.update({ind_wor: {
'position': ind_wor,
'word': wor
}})
sentences.update({ind_sen: {
'position': ind_sen,
'sentence': sen,
'words': words
}})
contents.update({ind_par: {
'position': ind_par,
'paragraph': par,
'sentences': sentences
}})
return contents
def _parse_dictionary(self):
all_paragraphs = []
all_sentences = []
all_words = []
for i in range(len(self.content)):
all_paragraphs.append(self.content.get(i+1).get('paragraph'))
sents = self.content.get(i+1).get('sentences')
for j in range(len(sents)):
all_sentences.append(sents.get(j+1).get('sentence'))
words = sents.get(j+1).get('words')
for k in range(len(words)):
w = words.get(k+1).get('word')
all_words.append(w)
paragraphs_dict = {}
for ind, p in zip(list(range(1, len(all_paragraphs) + 1)), all_paragraphs):
paragraphs_dict.update({ind: {
'position': ind,
'paragraph': p
}
})
sentences_dict = {}
for ind, s in zip(list(range(1, len(all_sentences) + 1)), all_sentences):
sentences_dict.update({ind: {
'position': ind,
'sentence': s
}
})
word_dict = {}
for ind, w in zip(list(range(1, len(all_words) + 1)), all_words):
word_dict.update({ind: {
'position': ind,
'word': w
}
})
return paragraphs_dict, sentences_dict, word_dict
def _get_unique_words(self):
all_words = []
for i in range(len(self.words)):
all_words.append(self.words.get(i+1).get('word'))
return list(set(all_words))
def _content_to_df(self):
_tabu_tuples = []
for cont, ty in zip(
[self.paragraphs, self.sentences, self.words],
['paragraph', 'sentence', 'word']
):
for _posi in range(1, len(cont)):
_info = cont[_posi]
_value = _info.get(ty)
_tabu_tuples.append((self.id, ty, _posi, _value, hashlib.md5(_value.encode()).hexdigest()))
df = pd.DataFrame(_tabu_tuples, columns=['document_id', 'type', 'position', 'value', 'hashed_content_md5'])
return df
def write_excel(self, target):
# Valid File
if self.check_valid_ext(target, "xlsx") is False:
raise ValueError(f"Target file not good {target}")
with pd.ExcelWriter(target, mode='w') as writer:
self.document_dataframe.to_excel(writer, sheet_name='DATA', engine='xlsxwriter')
def write_parquet(self, target):
# Valid File
if self.check_valid_ext(target, "parquet") is False:
raise ValueError(f"Target file not good {target}")
self.document_dataframe.to_parquet(path=target)
def get_id(self):
return self.id
def get_document(self):
return self.document
def get_content(self):
return self.content
def get_paragraphs(self):
return self.paragraphs
def get_sentences(self):
return self.sentences
def get_words(self):
return self.words
def get_tokens(self):
return self.tokens
def get_metadata(self):
return {
'id': self.id,
'language': self.language,
'title': self.title,
'subject': self.subject,
'entity': self.entity,
'source': self.source,
'type': self.type,
'issued_date': self.issued_date,
'effective_date': self.effective_date,
'is_internal': self.is_internal
}
def to_dataframe(self):
return self.document_dataframe
def statistics(self):
return {
'paragraph': len(self.content),
'sentence': len(self.sentences),
'word': len(self.words)
}
def update_metadata(self, path: str = None):
fi = os.path.basename(path)
fin, fie = os.path.split(fi)
if os.path.isfile(path) and fie == 'yml':
if path != self.file_metadata:
# Metadata
try:
with open(self.file_metadata) as f:
metadata = yaml.load(f, Loader=yaml.FullLoader).get('metadata')
except Exception:
self.file_metadata = None
raise Exception
# Update
self.language = safe_dict_extract(d = metadata, key = 'language')
self.title = safe_dict_extract(d = metadata, key = 'title')
self.subject = safe_dict_extract(d = metadata, key = 'subject')
self.entity = safe_dict_extract(d = metadata, key = 'entity')
self.source = safe_dict_extract(d = metadata, key = 'source')
self.number = safe_dict_extract(d = metadata, key = 'number')
self.type = safe_dict_extract(d = metadata, key = 'type')
self.issued_date = safe_dict_extract(d = metadata, key = 'issued-date')
self.effective_date = safe_dict_extract(d = metadata, key = 'effective-date')
self.is_internal = safe_dict_extract(d = metadata, key = 'is-internal')
def search(self, keyword: str, limit: int = 10, threshold: int = 50):
_satified = []
for wo, ty in zip(
[self.paragraphs, self.sentences, self.words],
['paragraph', 'sentence', 'word']
):
seach_pool = wo.values()
_pool = process.extract(keyword, seach_pool, limit=limit)
for w, thr in _pool:
if thr >= threshold:
_satified.append((ty, w, thr))
return _satified
@staticmethod
def check_valid_ext(path, ext):
ffile = os.path.basename(path)
_, fext = os.path.splitext(ffile)
result = False
if fext == "." + ext:
result = True
return result
def _check_file(path):
result = False
if os.path.isfile(path):
result = True
return result
def safe_dict_extract(d: dict | None = None, key: str = None):
if d is None:
d = {}
return d.get(key) if d.get(key) is not None else None